As part of my MEng at UofT I got the chance to take an introductory course to data analytics and machine learning. Amongst the large number of topics covered in the course one of the topics which I found the most fascinating, and challenging, was Natural Language Processing (NLP). NLP allows a data scientist to extract meaningful information within a database of text. This information can be used in a variety of ways such as guiding a business in a new direction, finding trends in voting data to help predict the sentiment of a particular party, or in the case of my project, identify trends related to the current health crisis around the world.
Prior to applying any machine learning algorithms the first task is always to perform data cleaning. For me this was always a challenging task because identifying what text information to keep wasn’t always straight forward. As an example, we were given a dataset of research papers which were dated from 2000 to 2021. Within this text there could be numerical information, like the technical name of a vaccine, or simple numbers which held no meaning in the larger dataset. This is specially challenging when a dataset contains over 400,000 data samples. The idea of going one by one and identifying which numerical strings I wanted to keep would not be a feasible idea. Specially if I wanted to meet my submission deadline. So, from the start I wanted to remove any numbers which showed up in my database. In particular numbers which showed up in abstracts or titles. But why would having numerical data be an issue? The issue arises when figuring out what features should be passed on to the machine learning portion of the exercise. If the abstract text data was split every time there was a space, but no thought was made into cleaning out numbers which had no value, one could easily end up with thousands of features which would act as noise for our NLP algorithm. Everything has a catch, in my case by filtering out numerical data from the abstracts I had no way of identifying if there where important numbers in the dataset. At the time of writing the vaccines for the current pandemic have numerical information which I lost during the data cleaning portion.
So I’ve removed numbers from my dataset but now how should text data be cleaned? One way of simplifying text data is to use the concept of stemming. Stemming text data reduces words into their stem like taking the words “take, taken, takes, taking” and within the English language realizing that the word “Take” is the common stem for all 4 words. I can then use a feature encoding method like One Hot encoding and generating a feature dataset which translated the text data into a sequence of rows with the stems of all the words in the abstracts. There is an issue with this approach, stemming does not take into account the context in which a word was used. If I’m interested in identifying the sentiment found in a body of text, stemming can remove this context in a sentence and therefore remove useful information. So, what can I do to maintain some context information within a body of text? Lemmatization would be an approach to take. Lemmatization actually combines the fact that a word was used a verb, adjective, noun and uses this to filter the text information. What is the downside of going with this approach? You now need to analyze how the word was used in a sentence which increases the computation time for encoding text. In my case this was a tradeoff worth making.
Text data has been cleaned but before some feature encoding is done, what kinds of trends did I see in the data? Well check it out! I did some more work for the titles of the papers given to us but these are the word clouds for the titles in our dataset.
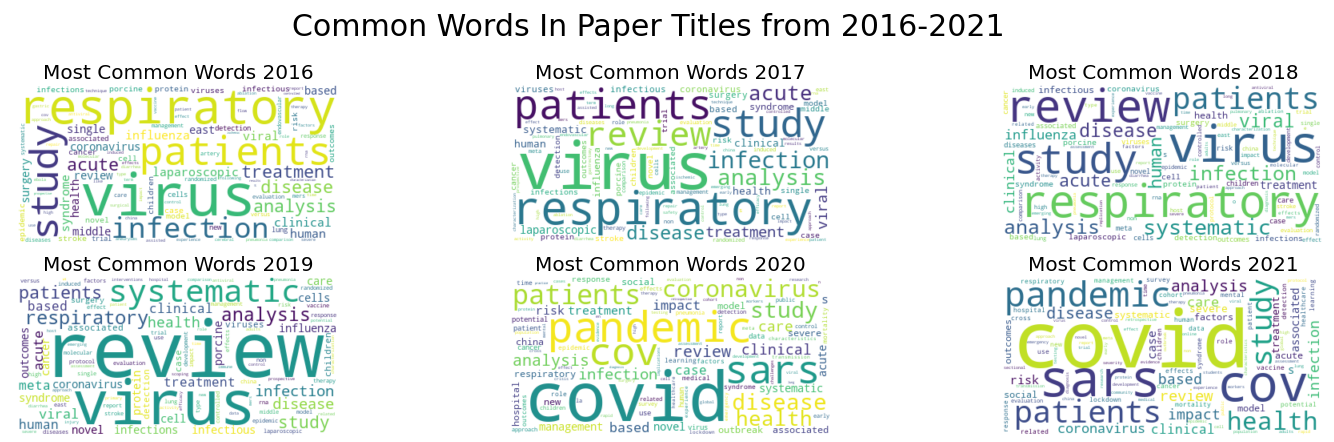
After my day cleaning I decided to focus on the abstract data from the years 2020 and 2021 as this was the focus for my final project. So I had to encode the text data but feature encoding can be performed in a variety of ways. One method is called Bag of Words (BOW) which uses One Hot encoding to generate a matrix of 0 or 1 when a feature is present in sample. This method only tells me when a feature is present but not the frequency in which it appears in a dataset. Depending on the algorithm used to analyze the data this method can generate a sparse matrix to save on memory for large datasets. Another method for encoding data is called Term Frequency-Inverse Term Frequency (TF-IDF) which encodes the frequency in which a feature appears in a sample. This adds complexity to our feature set. In the end I decided to look at the feature set and identify clusters of present in the BOW and TF-IDF encoding methods. During my encoding process I ended up with ~10,000 features and ~200,000 samples of data. To identify clusters of data I applied a dimensionality reduction process called Principal Component Analysis (PCA) with the help of the Sklearn. One thing to keep in mind when performing feature reduction with PCA, the amount of RAM your computer can use. In my case running PCA used about 20GB of RAM.
Once the features where reduced to 2D the unsupervised Machine Learning method called K-Nearest Neighbors (KNN) was used to identify clusters of data in the reduced dataset. Again this was performed with the help of Sklearn as this function is already implemented. So what did all this process produce?
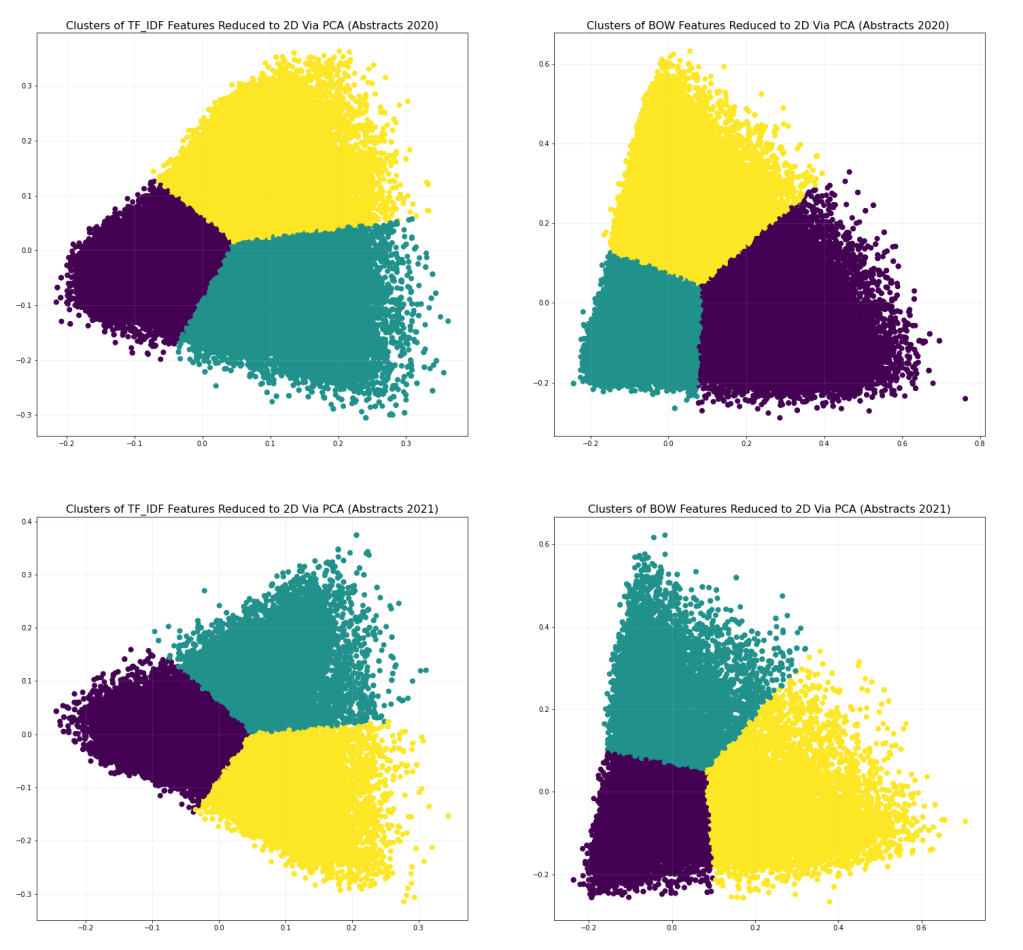
These clusters were useful in identifying which features were relevant in the text information being analyzed. However this is just one approach for identifying key features in text information.
This exercise was a huge eye opener for me when it came to analyzing text in a large dataset. Being able to extract key words and trends in data is not an exact science but luckily there are a lot of resources out there to help complement what I was taught in class. One huge resource was the website called “Towards Data Science” which also goes into detail in explaining concepts used in data analytics.
It’s remarkable how easily we can look at large bodies of data and extract trends in the data. Next time you look at a body of text consider how your brain extracts emotion, relevant information and think how you could program a computer to do the same process.

Leave a comment